En la entrega anterior de esta serie, vimos las cuatro formas en las que podemos ignorar ciertos ficheros de forma que no se incluyan en nuestros repositorios.
En este artículo vamos a ver en qué orden se aplican estas cuatro maneras de leer los patrones y qué ocurre cuando en ellos tenemos patrones contradictorios.
Patrones contradictorios
Supongamos que tenemos los siguientes patrones en los ficheros exclude y .gitignore:
#.git/info/exclude *.phar *.p
#.gitignore !*.php
Estos patrones son contradictorios ya que en el primer caso estamos ignorando los ficheros con extensión .php y en el segundo estamos diciendo que no se ignoren (ese es el significado del signo de exclamación «!» inicial en el patrón).
¿Qué va a pasar? Dado que el fichero .gitignore tiene prioridad sobre el fichero .git/info/exclude, los ficheros se incluirán en el repositorio. Si abrimos SourceTree en nuestro proyecto veremos lo siguiente:
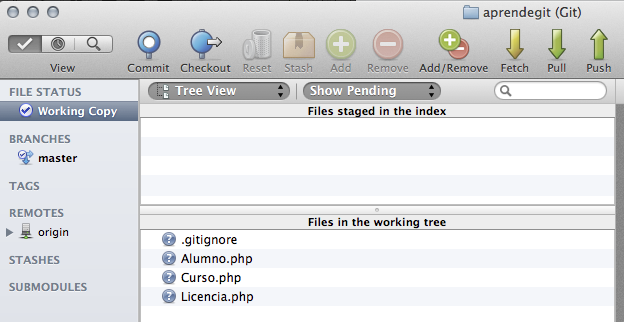
La regla es que git revisa por orden la línea de comandos, el fichero .gitignore, el fichero exclude y el fichero indicado por core.excludesfile. El primero último de ellos que contenga un patrón que explícitamente ignore o no un fichero dado, es el que aplica.
¿Qué pasa si dentro de un mismo fichero existen reglas contradictorias? Imagínate un fichero .gitignore como el siguiente:
# .gitignore !*.php # Otros patrones .... # Un compañero de equipo añade días después la siguiente regla *.php
Git utiliza la última regla, por lo que los ficheros se ignoran y no podríamos añadirlos al repositorio: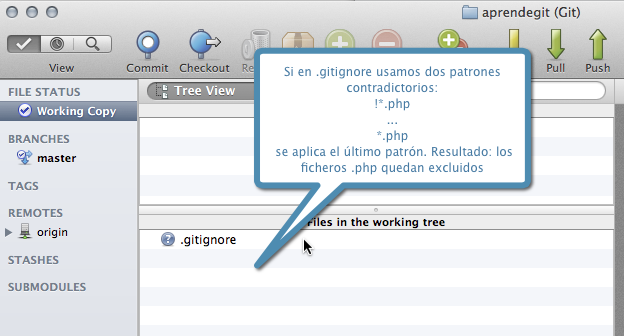
.git/info/exclude vs .gitignore vs core.excludesfile
Entendido cómo funciona el orden de prioridades ¿qué patrones ponemos en cada una de las tres opciones que nos da git?
- En .gitignore pondremos aquellos patrones que queremos que sean iguales en todos los clones que existen del repositorio. Todos los miembros del equipo los comparten. Es por ello que este fichero debe incluirse en el repositorio. Este es un buen lugar para ignorar ficheros de log y cache, configuraciones, claves privadas, etc.
- En .git/info/exclude se incluyen patrones que se van a aplicar sólo a nuestra copia local y no se van a distribuir al resto de miembros del equipo. Este fichero es útil cuando por ejemplo, creas una rama local para desarrollar una determinada característica de la aplicación, y necesitas ignorar ciertos ficheros sin que el resto del equipo se vea afectado por ello.
- En el fichero indicado por la variable core.excludesfile, incluimos aquellos patrones que queremos ignorar de forma global en todos los repositorios. Este es un lugar para incluir los ficheros del proyecto generados por nuestro entorno de desarrollo. Por ejemplo, si estamos trabajando con PHPStorm o RubyMine, incluiríamos el siguiente patrón:
.idea/
Para saber qué fichero es el que se indica en la variable core.excludesfile, usamos el comando git-config:
# git config --get core.excludesfile /home/myuser/.gitignore_global
Si queremos modificar la ruta al fichero utilizamos la opción –global del comando git-config:
# git config --global core.excludesfile /home/myser/myconfig/mygitignore # git config --get core.excludesfile /home/myuser/myconfig/mygitignore
Por una cuestión de comodidad, denominaremos de ahora en adelante este fichero como .gitignore_global, entendiendo que modificando esta opción de configuración, este fichero puede tener otro nombre y estar en una ruta diferente.
¿Conviene incluir en el repositorio los ficheros de configuración del entorno de desarrollo?
Una conversación que he tenido ya en varias ocasiones con diferentes personas es si conviene o no incluir en el fichero .gitignore los ficheros de configuración del entorno de desarrollo, ya sea Eclipse, Netbeans, PHPStorm o cualquier otro.
Mi política es la siguiente:
- Si estás trabajando en un proyecto de software libre en el que puede participar cualquier persona, tendrías que incluir en el fichero todos y cada uno de los posibles IDE que los colaboradores utilicen. Esto complica el fichero innecesariamente y dificulta su mantenimiento. ¿Cuántos IDE o editores de texto diferentes utilizan todos los colaboradores de un proyecto? En este caso, lo mejor es que cada colaborador se responsabilice de configurar su fichero .git/info/exclude o .gitignore_global adecuadamente.
- Si estás trabajando en un equipo en el que todos sus miembros utilizan el mismo entorno de desarrollo, entonces sí que incluyo los ficheros del IDE en el fichero .gitignore. El motivo es que no usamos más de dos o tres IDE diferentes que se pueden gestionar fácilmente con 3 o 4 patrones en el fichero .gitignore.
De cara a trabajar con gente novata en git dentro del equipo, la mejor opción es la segunda. El motivo es que no necesitan hacer nada una vez clonan el repositorio para ignorar los ficheros del entorno de desarrollo. Así les facilitamos un poco el trabajo al principio.
Esto es todo por hoy. En la siguiente entrega veremos los diferentes patrones que podemos utilizar para ignorar ficheros.