En esta entrada, la tercera de una serie de tres, explicamos qué es un pull request y cómo funciona en github.
Recordamos brevemente qué es lo que nuestros usuarios aalbagarcia y aprendegit-user1 hicieron en las dos entradas anteriores:
- El usuario aalbagarcia crea un repositorio en github: https://github.com/aprendegit/fork
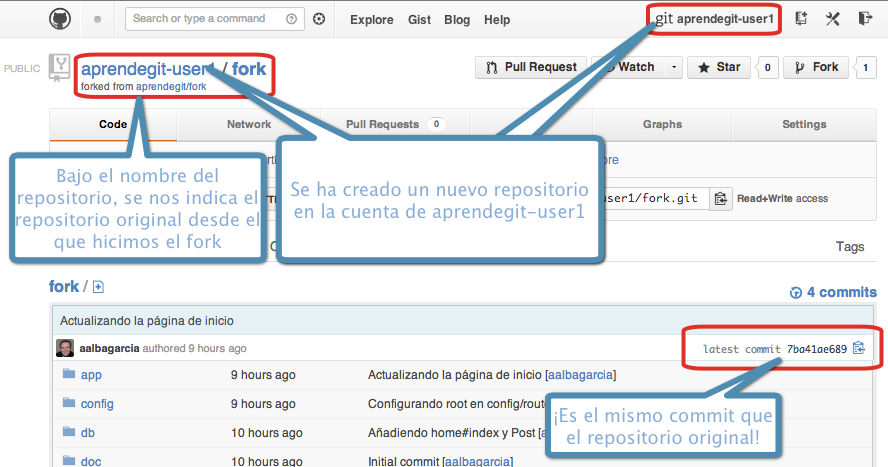
- El usuario aprendegit-user1 crea un fork (bifurcación) para trabajar en él: https://github.com/aprendegit-user1/fork
- Los dos usuarios realizan modificaciones cada uno en su repositorio, cada uno de ellos hace un commit y posteriormente un push. Cada uno sube los cambios a su correspondiente repositorio
- El usuario aprendegit-user1 configura un repositorio remoto adicional (upstream) e incorpora, haciendo un merge, los cambios en el código que hizo aalbagarcia. Después de hacer el merge, aprendegit-user1 hace un push para actualizar su repositorio remoto.
Lo último que nos falta por hacer es que el usuario aalbagarcia, que es el propietario del repositorio inicial (https://github.com/aprendegit/fork), incorpore el trabajo del usuario aprendegit-user1 que se encuentra en el fork https://github.com/aprendegit-user1/fork.
¿Qué es un pull request?
Un pull request es una petición que el propietario de un fork de un repositorio hace al propietario del repositorio original para que este último incorpore los commits que están en el fork. En el caso que nos ocupa, el usuario aprendegit-user1 le enviará la petición a aalbagarcia para que este último incorpore los commits que tiene en su fork.
Lo primero que hará el usuario aprendegit-user1 será crear una rama que apuntará al último commit que ha hecho y que contiene las modificaciones a la página de inicio. El procedimiento es el de siempre:
- Se selecciona a la izquierda la rama master y se hace clic sobre el último commit de la rama
- Se hace click sobre el icono «Branch»
- Se introduce el nombre de la rama, en este maso mycommits
- Se hace clic sobre «Create Branch»
Si se usa la línea de comandos, la secuencia sería:
$ git checkout master
Switched to branch 'master'
$ git checkout -b mycommits
Switched to a new branch 'mycommits'
Una vez creada la rama, el usuario aprendegit-user1 hace push de la rama «mycommits» a su fork:
- Se selecciona la rama mycommits a la izquierda asegurándonos de que esta queda como rama activa haciendo doble clic sobre ella
- Se selecciona el último commit de la rama
- Se hace clic sobre el icono Push de la bara de herramientas
- En el desplegable, se selecciona en la columna «Push?» la rama mycommits y se marca en la columna de la derecha (Track) la rama local como tracking branch.
- Se hace clic sobre OK.
La secuencia de comandos sería
$ git checkout mycommits
$ git push -u origin mycommits
Total 0 (delta 0), reused 0 (delta 0)
To git@github-aprendegit-user1:aprendegit-user1/fork
* [new branch] mycommits -> mycommits
Branch mycommits set up to track remote branch mycommits from origin.Al terminar, el estado del repositorio es el siguiente:

Solicitando el pull request
En este momento, el usuario aprendegit-user1 accede a su cuenta de github y abre en su navegador la página de su fork https://github.com/aprendegit-user1/fork.
Una vez hemos accedido, cambiamos a la rama mycommits como se indica en la siguiente captura:
Una vez se ha cambiado a la rama mycommits, aprendegit-user1 hace clic sobre el botón «Pull Request»
Esta es la pantalla que se presenta a aprendegit-user1:
En la parte superior, aprendegit-user1 selecciona la rama que contiene los commits que aalbagarcia (el destinatario del pull request) debe incorporar en su repositorio. En la parte de abajo se ven tres pestañas en las que se puede:
- Poner un título y descripción al pull request
- Ver los commits que aalbagarcia incorporará al repositorio si acepta el pull request (pestaña Commits)
- Ver un diff que los cambios que se incluyen en los commits (pestaña Files Changed)
Es una buena práctica poner un título y descripción que reflejen el motivo del commit. Estos pull requests los ven todos los colaboradores del proyecto (si el proyecto es público lo ve todo el mundo) Así que aunque aalbagarcia y aprendegit-user1 hayan hablado por teléfono acerca de este pull request, el resto del mundo seguramente no ha escuchado la conversación. Pensando en el resto del equipo, aprendegit-user1 incluye un mensaje descriptivo de qué contiene el pull request. Cuando termina, hace clic sobre el botón «Send Pull Request». Esta es la pantalla a la que aprendegit-user1 llega después de enviarlo:
La captura es bastante sencilla de entender. Vemos el título y descripción introducidos por aprendegit-user1, los commits y una interfaz para intercambiar comentarios con el equipo.
Aunque en pequeño, se nos indica qué es lo que tendríamos que hacer para añadir commits a este pull request: enviar más commits a la rama «mycommits» del fork de aprendegit-user1.
¿Porqué podemos necesitar añadir más commits? Imagínate que el equipo revisa el pull request y se determina que todavía queda trabajo pendiente de hacer. ¿Cómo se procede? aprendegit-user1 continúa el trabajo en la rama rama «mycommits» de su fork y cuando termina lo sube a su repositorio remoto. El pull request se actualiza y todo el equipo puede ver el nuevo código. Esto lo veremos en detalle en otro artículo, de momento, seguimos con el proceso.
Aceptando el pull request
Cuando aprendegit-user1 envía el pull request, Github envía al propietario un email avisándole de que tiene un pull request listo para revisar. En este caso, el usuario aalbagarcia recibe el email, accede a su cuenta de Github y va a su repositorio https://github.com/aprendegit/fork:
En esta pantalla, seleccionamos la pestaña «Pull Requests» y accedemos a una interfaz que nos muestra todos los que tenemos. Dado que este es el primero, en este listado seleccionamos el único que hay:
Cuando aalbagarcia selecciona «Añadiendo logotipo», accede a una pantalla muy parecida a la que hemos visto con el usuario aprendegit-user1. En la siguiente captura indico cuáles son las diferencias:
Las diferencias son:
- Existe un botón «Merge pull request» que el propietario aalbagarcia utilizará para incorporar los commits al repositorio
- Existe un botón «Close» que el propietario utiliza para cerrar el pull request sin incorporar los cambios
Una vez revisado el código y confirmado que todo está bien, aalbagarcia hace clic sobre el botón «Merge Pull Request». En ese momento Github le pedirá que introduzca un comentario para el merge commit. Una vez introducido, aalbagarcia hace clic sobre el botón «Commit merge» y ya está, Github automáticamente cierra el pull request. También envía un email a los dos interesados (aalbagarcia y aprendegit-user1) avisándoles de que se han incorporado los cambios en el repositorio.
Si volvéis a la página de commits del repositorio en github (https://github.com/aprendegit/fork/commits/master) veréis que tras hacer el pull request, aparece un nuevo commit en el repositorio:
¿Cómo quedan los repositorios de aalbagarcia y aprendegit-user1?
En este momento, el repositorio remoto de aalbagarcia ya contiene el merge commit que se ha creado a través del pull request. La pregunta es ¿el de aprendegit-user1 también? ¿verán estos nuevos commits los dos usuarios?
…la respuesta es que, efectivamente, no lo verán hasta que hagan un fetch en sus respetivos repositorios. Tras hacer los dos usuarios un fetch de todos sus repositorios remotos (recuerda que aprendegit-user1 tiene 2 remotos, origin y upstream) así quedan sus respectivas copias de trabajo:

Para terminar:
- aalbagarcia tiene que hacer un merge de la rama origin/master a la rama master
- aprendegit-user1 tiene que hacer un merge de la rama upstream/master a la rama master y después hacer un push de su rama master
Una vez hecho esto, los repositorios quedan de la siguiente manera:

Y como podéis ver, están sincronizados.
¿Quieres hace un pull request?
Si quieres hacer tú mismo el proceso para ver cómo funciona, ve al repositorio https://github.com/aprendegit/fork, haz un fork y envíanos las modificaciones siguiendo los pasos que hemos seguido en esta serie de artículos. Si tienes alguna duda no dudes en preguntarnos.
Seguiremos hablando de pull requests, aunque eso ya será en otros artículos.










 del repositorio original al fork")