En la primera parte de esta serie vimos cómo crear en bitbucket nuestro primer repositorio. Partiendo este punto, en esta entrada veremos cómo:
- Subir el código fuente al repositorio
- Crear un fichero README con información sobre el repositorio
- Enviar el fichero README a Bitbucket mediante push
Paso 1: Clonar el respositorio en nuestro ordenador
Lo primero que tenemos que hacer, una vez creado el repositorio en bitbucket, es clonar el repositorio en nuestra máquina. Si estáis trabajando con un Mac, como es mi caso, y habéis instalado previamente SourceTree, podéis hacer clic en la parte superior derecha derecha en el botón «Clone» y posteriormente sobre el botón «Clone in SourceTree».
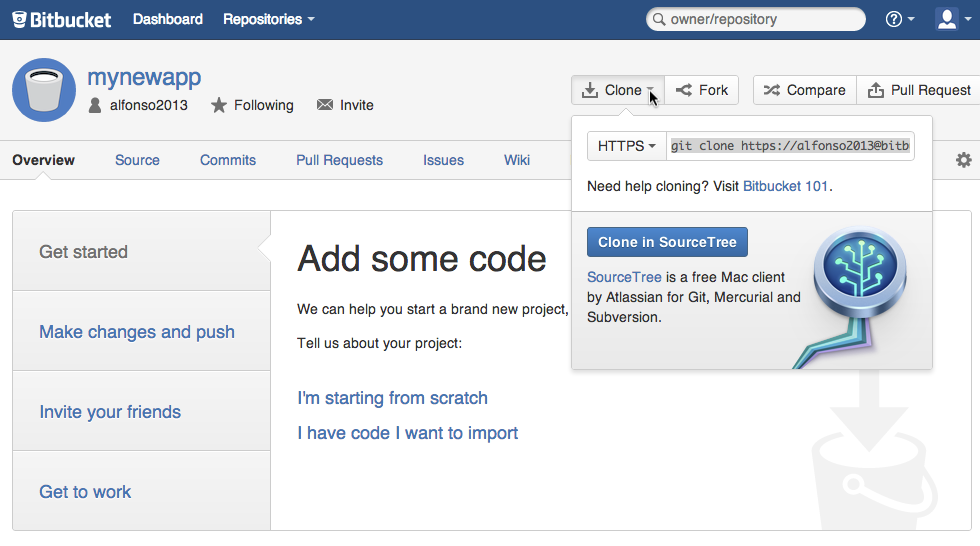
Cuando hagáis clic sobre el botón, se abrirá la aplicación y nos pedirá que seleccionemos una ruta en la que guardar el repositorio y un nombre corte (Bookmark Name) para localizarla rápidamente en el listado de repositorios de SourceTree:
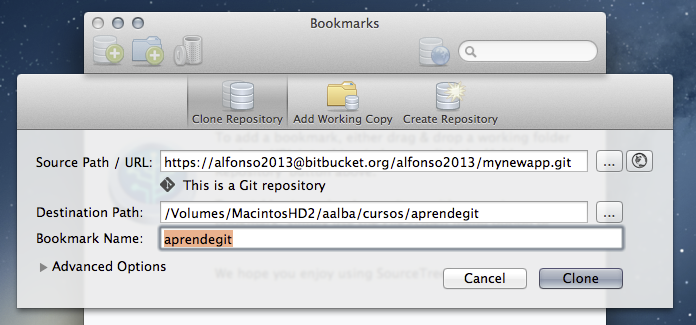
Una vez le demos al botón «Clone», SourceTree nos mostrará el repositorio en el listado:
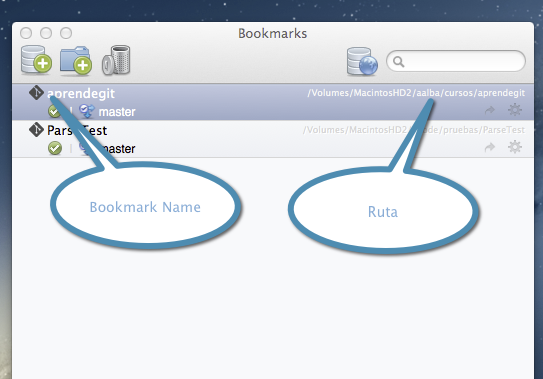
Si todo ha ido bien, ya estamos listos para dar el siguiente paso.
Paso 2: Crear el fichero README
Siempre que trabajemos con Bitbucket o github, es muy conveniente tener un fichero README en la raíz de nuestro repositorio, así que vamos a crearlo.
Lo primero y muy importante es que SourceTree no es un editor de código, tampoco es un IDE, es decir, no nos sirve para modificar el contenido de los ficheros:
- Cuando programes tus tests y clases, ajustes tus ficheros de configuración o maquetes la nueva versión de la web, seguirás usando tu editor o IDE favorito para hacer tu trabajo
- Cuando tus tests estén todos en verde, hayas terminado una una versión de tu página HTML, o tengas la configuración adecuada de tu sistema, cambiaremos a SourceTree para guardar en el repositorio el trabajo que hemos realizado [1]
Vamos a la carpeta en la que hemos clonado el repositorio y creamos un fichero README.md con el siguiente contenido:
Una vez creado el fichero, dejamos el IDE o editor de texto que hayamos utilizado y volvemos a SourceTree. En la pantalla principal, abrimos el repositorio que acabamos de crear haciendo doble clic sobre él en el listado. Al hacerlo, se nos abrirá una pantalla similar a la que se muestra a continuación:
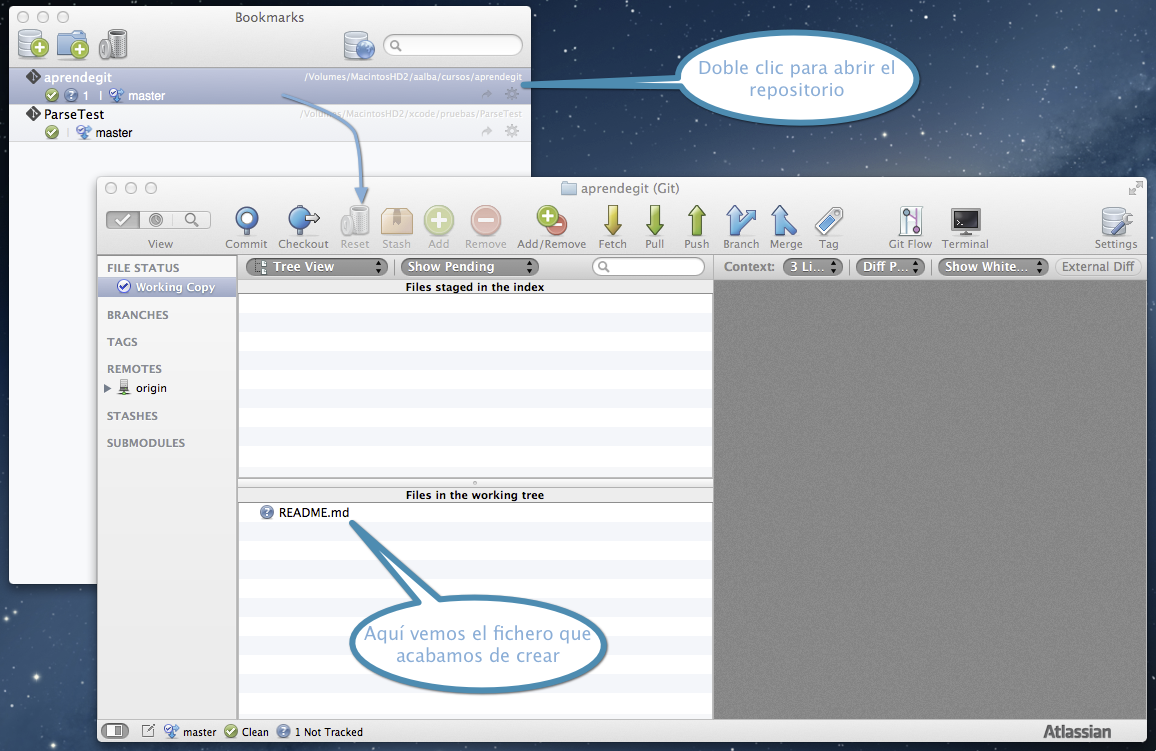
En el área de trabajo, situada en la parte inferior, vemos el fichero README.md que acabamos de crear. ¡Ha llegado el momento de subirlo a Bitbucket!
Paso 3: Subir el fichero a Bitbucket
Para hacerlo, seleccionamos el fichero README.md en el área de trabajo y le damos al botón «Add» que tenemos en el menú superior. También podemos arrastrarlo a la sección «Files staged in the index» que está justo encima:

Una vez tenemos el fichero en el área de ensayo (staging area) hacemos un commit presionando el botón «Commit» de la barra de herramientas. Se abrirá la siguiente ventana en la que debemos escribir un mensaje que describa qué hemos hecho. En este caso es sencillo: «Añadiendo el fichero README.md»:

Cuando terminemos, presionamos el botón «Commit». Al cerrase la ventana, fíjate que a la izquierda, en la sección «Branches» nos aparece una nueva rama que SourceTree por defecto ha llamado «master»:
El último paso es enviar el commit a Bitbucket. Presionamos el icono Push en la barra de herramientas, en la ventana emergente seleccionamos la rama local master y a continuación presionamos OK:
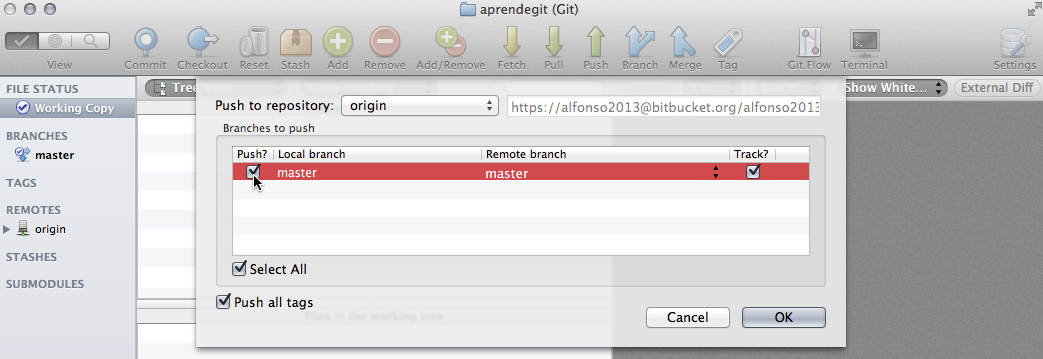
Nos pedirá la contraseña de nuestro usuario de Bitbucket, la introducimos y presionamos «Aceptar». Si tenemos conexión de red y no nos hemos equivocado al poner la contraseña, la ventana emergente se cerrará y volveremos a la pantalla del repositorio. Si se produce algún error, SourceTree nos avisará y nos mostrará el mensaje que git ha generado.
Pues ya está, si no nos ha avisado SourceTree de que algo ha ido mal, significará que nuestro commit ha sido correctamente enviado al repositorio remoto. Volvemos al navegador web y recargamos la página del repositorio, que tendrá un aspecto similar a este:

donde vemos cómo Bitbucket nos muestra el contenido del fichero README.md, la actividad reciente del repositorio y la información general del repositorio en la parte derecha.
Esto es todo, ya hemos subido el primer fichero y tenemos el repositorio listo para empezar a trabajar en nuestro proyecto. Si tenéis consultas, preguntas o comentarios sobre este procedimiento, no dudéis en preguntarnos.
————-
[1] Este tener que cambiar del IDE al SourceTree y del SourceTree al IDE no siempre es necesario: a día de hoy casi cualquier entorno de desarrollo dispone de módulos de integración con sistemas de gestión de código. Con estos módulos es posible hacer el commit y el push que hemos hecho en este artículo sin necesidad de abandonar el IDE.
Muy bueno el tuto, me vino excelente.
¡Gracias! me alegro de que te haya sido de ayuda.
Hola Alfonso,
Muy interesante el tutorial. Actualmente estoy estudiando estas herramientas y has explicado muy bien como conectar bitbucket con sourcetree. Tengo una duda, cuando he instalado sourcetree en windows me ha preguntado para instalar git de 3 formas diferentes. Podrías orientarme en la instalación de Sourctree y qué es necesario para su correcta instalación y posterior conexión con Bitbucket?
Muchas gracias .
Hola Oihana:
Ahora mismo no recuerdo cuáles son las tres maneras de instalar sourcetree (y no tengo un windows a mano para probarlo). Te comento las dos que yo conozco:
Si no te quieres complicar y la versión que se distribuye con Sourctree te vale, la primera es la opción más rápida. Si no usas la línea de comandos no vas a echar nada de menos.
Si quieres estar a la última y usar la línea de comandos al 100%, entonces usas la segunda opción. Te instalas git por tu cuenta y luego le dices a sourcetree dónde está el ejecutable de git para que lo use.
Espero haberte ayudado.
Un saludo,
Alfonso
Hola Alfonso,
Muchísimas gracias, ¡es justo lo que necesitaba!.
Tengo otra duda respecto a la metodología usada para cuando se finaliza un proyecto. Pongamos que hemos estado desarrollando un website utilizando bitbucket y con GUI como SourceTree. Una vez terminado el proyecto, se conecta directamente el repo de bitbucket a «producción / ftp de tu site», o se sube por ftp directamente desde tu local? o hay alguna otra forma? o bitbucket es solo para trabajar?
¡Gracias otra vez! ya se que igual son muchas preguntas a la vez, pero me parece interesante tener la perspectiva general a la hora de trabajar en un proyecto con control de versiones. Evidentemente, soy bastante nueva en esto 🙂
…vamos a ver, que creo que estás mezclando cosas ;-).
Por un lado está el trabajo diario que haces con git (para el que usas la línea de comandos, Sourcetree o cualquier otro GUI como bien dices). Como parte de tu trabajo diario, harás commits y los subirás a un servidor como bitbucket usando push de ciertas ramas.
Por otro lado, tendrás un proceso de despliegue en producción, independiente del repositorio aunque puede estar conectado con él. Dos ejemplos:
– Deploy manual: Decides una rama o etiqueta de tu repo, haces un zip y lo subes por FTP
– Deploy semi automático: te conectas por SSH a tu servidor y haces un pull de tu rama «production»
¿te he aclarado la duda (aunque sea un poco)?
Perfectamente Alonso.
Ahora ya tengo todo claro y ya me hago una idea de la dinámica y flujo de trabajo con control de versiones. Efectivamente, estaba mezclando conceptos.
Muchísimas gracias!
Hola Alfonso,
Muchas gracias por esta entrada ya que me esta sirviendo para meterme en el mundo de git.
Hay una cosa que no entiendo y es el significado de track en la ventana emergente que aparece al hacer el commit.
No sé si debo seleccionarlo siempre o que.
Perdón por esta pregunta tan tonta ;-P
Saludos y gracias.
Hola Óscar:
La pregunta no es tonta. Ese checkbox sirve para indicar si quieres que cal crear la rama remota, tu rama local se convierta en «tracking branch» de esa rama remota. Si vas a utilizar la rama para subir commits al servidor de manera regular, lo normal que sí la marques como «tracking».
Cuando una rama local es tracking branch de una rama remota, git puede decirte cosas como que vas 3 commits por detrás o dos por delante, por ejemplo, de lo que está pasando en el servidor. También sirve para que los comandos pull y push sepan a qué rama remota subir tus commits cuando los ejecutas a secas, es decir, poniendo «git pull» o «git push» nada más.
Puedes encontrar más información acerca de qué es un tracking branch en el capítulo 3 del libro de Pro git:
http://git-scm.com/book/en/Git-Branching-Remote-Branches#Tracking-Branches
(en español lo tienes aquí: http://git-scm.com/book/es/Ramificaciones-en-Git-Ramas-Remotas#Haciendo-seguimiento-a-las-ramas)
Un saludo y gracias por tus comentarios.
Muchas gracias por responder Alfonso.
Gracias también por aclararme la duda y por esos enlaces 😉
Saludos.
Hola alfonso una consulta para el trabajo en equipos como configuro los accesos y permisos, como puedo administrar las ramas creadas para cada usuario. Gracias
Hola Andrés:
Para poder ayudarte necesitaría un poco más de información sobre el tipo de infraestructura que estáis utilizando. ¿Dónde tenéis alojados los repositorios remotos? ¿gitolite, github, bitbucket, gitlab, vuestro propio servidor? Cada una de estas soluciones implementa los permisos de acceso a su manera. Recuerda que git no ofrece por defecto ningún tipo de control de acceso, son estas aplicaciones las que ponen la capa de autenticación por encima de git.
Hola gracias por tu respuesta, yo tengo alojado mi proyecto en bitbucket y a este le he configurado ramas para mi equipo. A estas ramas quiero asiganrle usuarios(miembros del equipo) para que solo trabajen en esas ramas, luego ya yo como administrador poder hacer los marge y demas sin tener complicaciones. Saludos.
Hola Andrés:
Bitbucket dispone de varias acciones para gestionar los permisos de las ramas. En este post de su blog puedes verlas:
http://blog.bitbucket.org/2013/09/16/take-control-with-branch-restrictions/
Puedes limitar pushes, evitar los borrados de ramas o impedir que se pueda reescribir la historia de una rama. Cada miembro tendría su rama a la que puede hacer push, tu te das permiso para hacer push en todas las ramas, impides que esas ramas se puedan borrar y con esto ya lo deberías tener.
Sólo una nota más. Yo he trabajado en un flujo parecido al que quieres hacer porque trabajaba con gente que no conocía bien la herramienta. Desafortunadamente mi experiencia no fue buena porque el flujo que escogí no fue el adecuado o yo no lo implementé correctamente. Las decisiones que tomé me llevaron a tener toda la responsabilidad, convertirme en un cuello de botella (si sólo uno puede o sabe hacer los merges es lo que pasa), un «single point of failure» (si me iba de fin de semana largo no había merges) y di lugar a que el resto del equipo se acomodase «descuidando» el repositorio y «pasando» de aprender a usar la herramienta. Lo comparto contigo para que no cometas los mismos errores que yo 😉
Muchas gracias por tu tiempo. Revisaré la información.
Saludos.
Hola Alfonso,
Estoy empezando en esto y quisiera saber si me podrías ayudar con este error…realice todos los pasos que dices pero cuando presiono push y le doy ok haciendo el proceso que tu dices me sale que:
git -c diff.mnemonicprefix=false -c core.quotepath=false push -v –tags –set-upstream origin master:master
remote: Invalid username or password. If you log in via a third party service you must ensure you have an account password set in your account profile.
fatal: Authentication failed for ‘https://[email protected]/anderson_suarez/primer_prueba.git/’
Pushing to https://[email protected]/anderson_suarez/primer_prueba.git
Completed with errors, see above.
Que puedo realizar al respecto?
De antemano de doy las gracias por compartir tus conocimientos.
A la hora de hacer clone existing repository (en servidor local) tengo un problema severo. Al hacer commit y push anda todo bien pero no figuran las modificaciones en bitbucket.
Antes me funcionaba pero ahora no. ¿Tendre que configurar el origin? No se como hacerlo ayuda. Luego subo todo a traves de FTP Filezilla a mi dominio.
Espero tu respuesta. Gracias por tu tiempo.