Seguimos con la serie de artículos sobre git-flow. Después de ver cómo pueden ayudarnos estas extensiones de git e instalarlas, vamos a empezar el desarrollo de nuestro proyecto utilizando git-flow.
Trabajaremos con una sencilla página HTML como ejemplo. No queremos complicar la explicación ni distraernos con el código fuente; el objetivo es entender el flujo que vamos a implementar con git.
Git-flow y metodologías ágiles
Los próximos artículos vamos a escribirlos en el contexto de las metodologías ágiles. Hablaremos de iteraciones, reuniones de planificación, reuniones diarias del equipo… El objetivo es poner git-flow en contexto y ver cómo nos puede ayudar.
Supongamos que ya hemos pasado por la reunión de planificación y hemos acordado en el equipo qué historias de usuario vamos a implementar en la primera iteración.
Las historias de usuario del primer sprint son las siguientes:
- H-1: La web dispondrá de una home con un menú de acceso al resto de páginas
- H-2: La página de inicio dispondrá de un hero con un texto y un botón de enlace al último artículo
Implementaremos la primera de las historias de forma manual y la segunda con git-flow. De esta forma entenderemos bien qué es lo que estas extensiones hacen por debajo.
Antes de empezar: git-flow-init
Dado que se trata de un proyecto nuevo, lo primero que haremos antes de empezar el desarrollo es, como no, crear el repositorio y prepararlo para usar git-flow. Para ello seguimos los siguientes pasos:
$ mkdir nuestro-proyecto
$ cd nuestro-proyecto
$ git init
$ git-flow init
No branches exist yet. Base branches must be created now.
Branch name for production releases: [master]
Branch name for "next release" development: [develop]
How to name your supporting branch prefixes?
Feature branches? [feature/]
Release branches? [release/]
Hotfix branches? [hotfix/]
Support branches? [support/]
Version tag prefix? [] v
Al ejecutar el último comando, entramos en un menú interactivo que nos va preguntando las opciones que aparecen arriba:
- Al inicializar git-flow, nos pregunta el nombre de la rama de producción y de la rama de desarrollo (master y develop respectivamente). Seleccionamos los nombres por defecto.
- Después nos preguntará los prefijos que asignará a las ramas de tipo feature, release, hotfix y support. Volvemos a seleccionar los nombres por defecto.
- Por último, nos pregunta el prefijo que queramos utilizar para etiquetar las versiones.
Si no os gustan los prefijos que usa git-flow por defecto, podéis utilizar otros. En un artículo posterior veremos como cambiar a posteriori estos nombres.
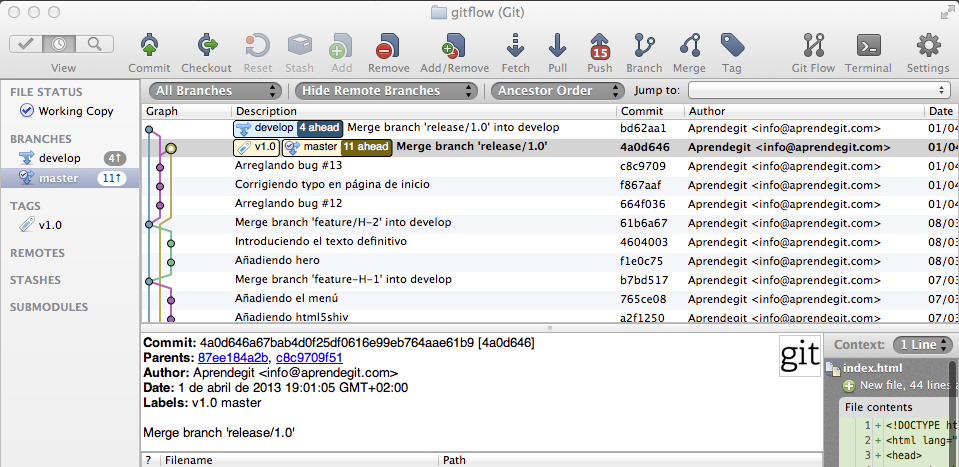
¿Y en qué estado queda nuestro repositorio después de hacer esto? Aquí tenéis una captura de SourceTree:

Estado del repositorio tras ejecutar git-flow
Vemos el commit inicial así como las ramas master y develop. Desde la línea de comandos, el repositorio tiene este aspecto:
$git branch -av
* develop 87ee184 Initial commit
master 87ee184 Initial commit
Desarrollando H-1: gestionando las ramas manualmente
En el proyecto, en una de las reuniones diarias, se decide que vamos a usar bootstrap para maquetar la web, así que en la primera historia descargaremos bootstrap, lo incluiremos en la carpeta vendor y crearemos la página de inicio (nota para los usuarios más avanzados: somos conscientes de que hay mejores maneras de añadir bootstrap al proyecto como por ejemplo usar submódulos. Usamos este enfoque más simple porque no queremos distraernos con detalles ajenos al objetivo de esta serie que es entender git-flow).
Dado que se trata de un desarrollo planificado que formará parte de un futuro release (la versión 0.1) usaremos una feature branch.
Recordamos: las feature branches nacen de la rama develop y se incorporan a esa misma rama. Así que creamos una nueva rama a partir de develop que llamamos feature-H-1:
$ git checkout -b feature-H-1 develop
$ git branch -av
develop 87ee184 Initial commit
* feature-H-1 87ee184 Initial commit
master 87ee184 Initial commit
Una vez creada la rama feature-H-1, hacemos la siguiente serie de commits:
- Añadimos bootstrap al proyecto
- Creamos la página de inicio
- Ponemos el menú
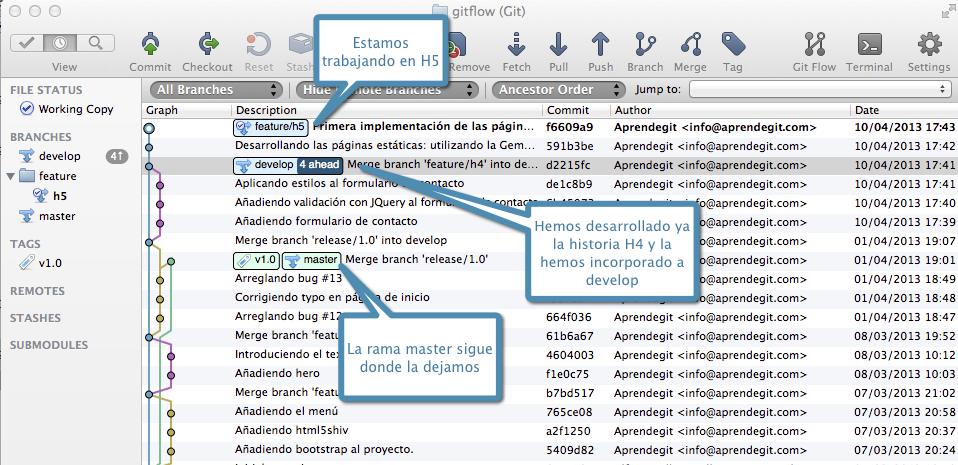
Cuando terminamos el desarrollo de la historia H-1, este es el estado de nuestro repositorio:

Así queda el repositorio cuando terminamos de hacer el desarrollo de la historia H-1 en la rama feature-H-1
Ya hemos terminado nuestra primera historia, así que ha llegado el momento de incorporar los cambios a la rama develop (recuerda, las feature branches se incorporan a la rama develop):
$ git checkout develop
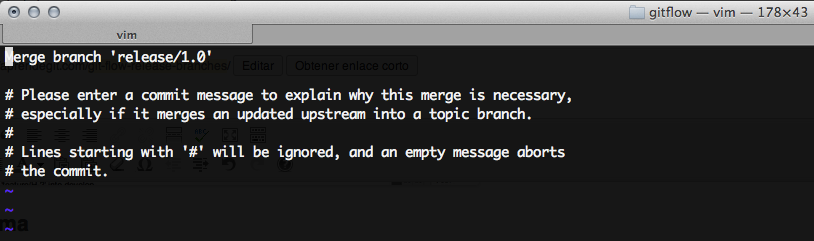
$ git merge --no-ff feature-H-1
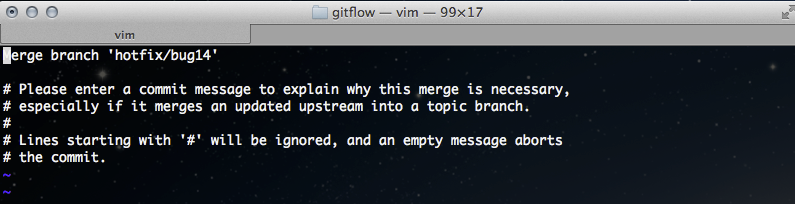
Si no sabes qué es la opción –no-ff y porqué la usamos, lee este artículo. Al ejecutar el comando se nos pide el mensaje para el merge commit:
Merge branch 'feature-H-1' into develop
# Please enter a commit message to explain why this merge is necessary,
# especially if it merges an updated upstream into a topic branch.
#
# Lines starting with '#' will be ignored, and an empty message aborts
# the commit.
Cuando guardamos y cerramos, este es el estado del repositorio:
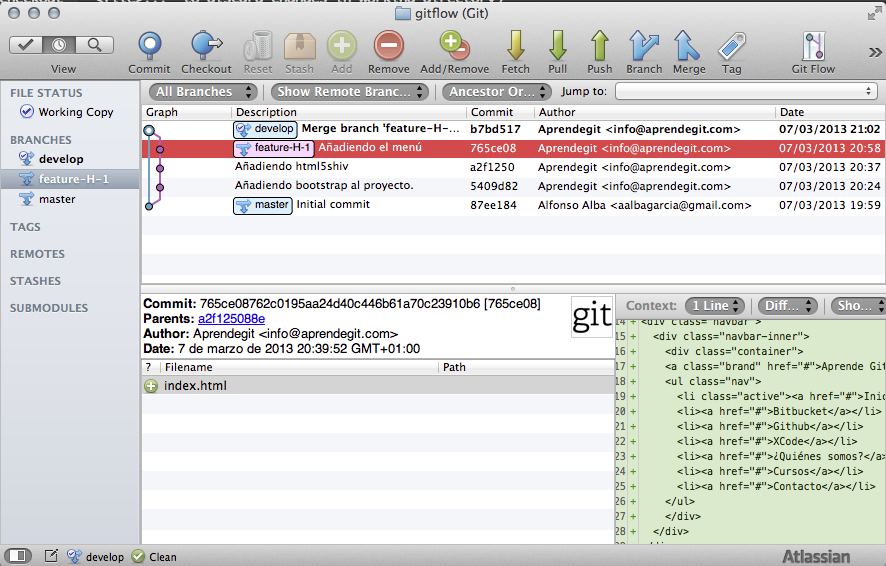
Estado del repositorio después de incorporar la rama feature-H-1
Como la rama feature-H-1 ha quedado visibles en el repositorio con un merge commit, podemos borrarla:
$ git branch -d feature-H-1
Deleted branch feature-H-1 (was 765ce08).
Pues bien, ya hemos terminado nuestra primera historia, vamos a por la segunda.
Desarrollando H-2: gestionando las ramas con git-flow
Para hacer esta historia, necesitaremos crear una nueva feature branch que llamaremos feature-H-2. Esta vez usaremos git-flow:
$ git-flow feature start H-2
Switched to a new branch 'feature/H-2'
Summary of actions:
- A new branch 'feature/H-2' was created, based on 'develop'
- You are now on branch 'feature/H-2'
Now, start committing on your feature. When done, use:
git flow feature finish H-2
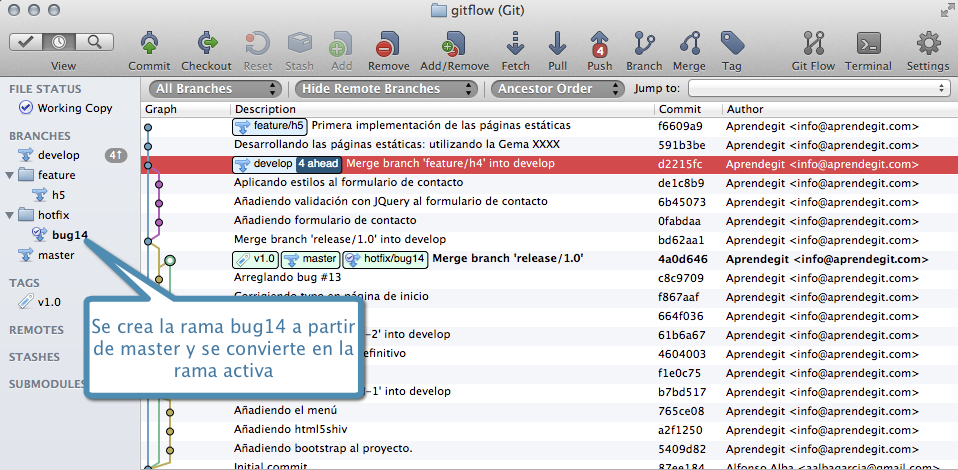
Notar que no necesitamos poner el prefijo “feature” para crear la rama, git-flow lo hace por nosotros. El propio git-flow se encarga de activar la rama feature/H-2 y de decirnos qué tenemos que hacer cuando terminemos. El estado del repositorio después de ejecutar el comando es el siguiente:
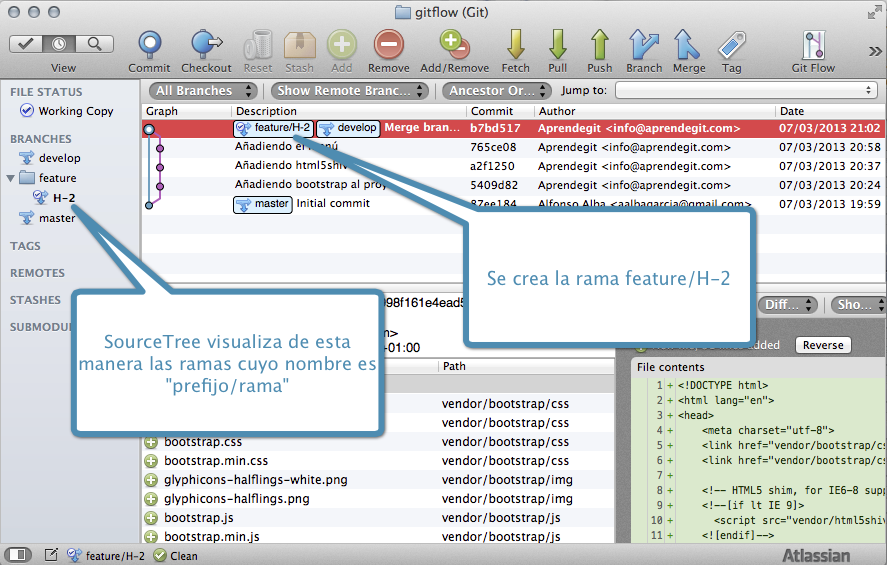
Estado del repositorio después de crear la rama feature/H-2 con gitflow
Con la rama creada, nos ponermos a trabajar. Implementamos el hero de la página de inicio y hacemos los commits correspondientes:
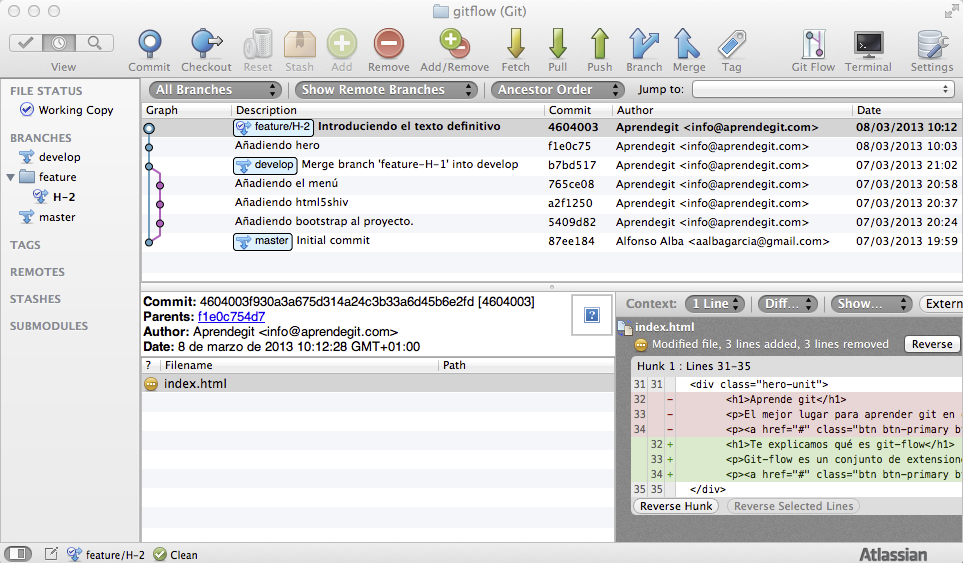
Estado de la rama feature/H-2 una vez terminado el desarrollo
Así vemos las ramas desde la línea de comandos:
$ git branch -av
develop b7bd517 Merge branch 'feature-H-1' into develop
* feature/H-2 4604003 Introduciendo el texto definitivo
master 87ee184 Initial commit
Si en un momento dado queréis listar las ramas de tipo feature desde la línea de comandos, basta con ejecutar git flow feature:
$ git flow feature
* H-2
Esto mismo es aplicable para las ramas hotfix, release y support.
Continuamos con el desarrollo. Revisamos y testamos nuestro código y cuando vemos que hemos terminado, utilizamos git-flow para cerrar la rama:
$ git flow feature finish H-2
Switched to branch 'develop'
Merge made by the 'recursive' strategy.
| 7 +++++++
1 file changed, 7 insertions(+)
Deleted branch feature/H-2 (was 4604003).
Summary of actions:
- The feature branch 'feature/H-2' was merged into 'develop'
- Feature branch 'feature/H-2' has been removed
- You are now on branch 'develop'
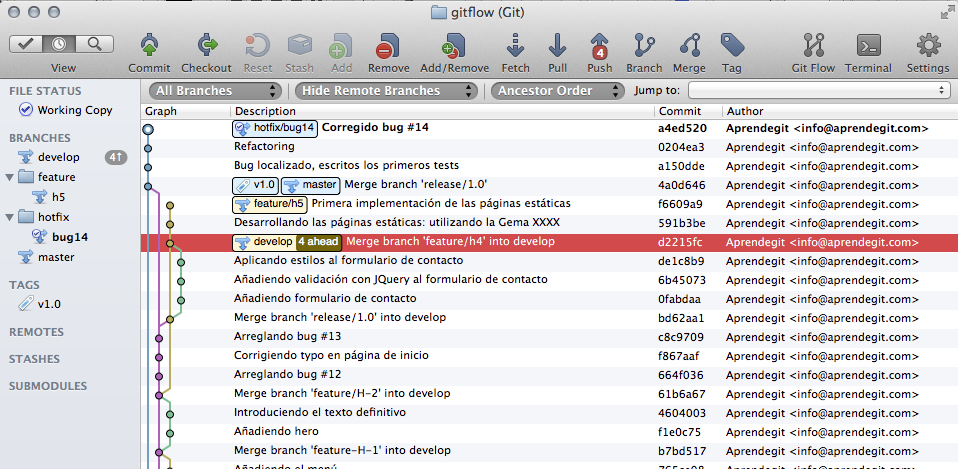
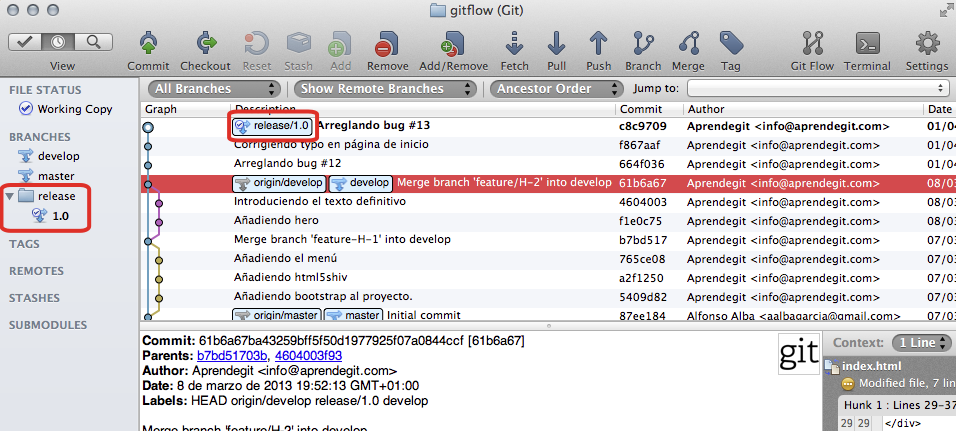
Es decir, hemos vuelto a la rama develop, se ha incorporado la rama feature/H-2 a develop y la feature branch se ha borrado. Después de ejecutar el comando, este es el resultado:
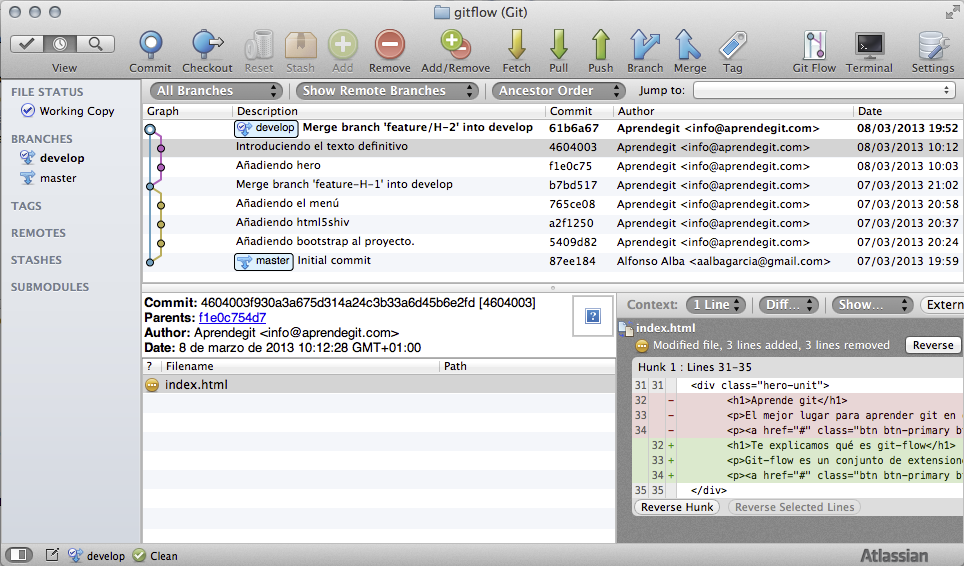
Estado del repositorio tras cerrar la feature branch
Si os fijáis, hemos hecho lo mismo ejecutando menos comandos.
En esta captura vemos cómo en este flujo de trabajo queda reflejado en la historia del repositorio de forma bastante limpia y clara, cuándo se empezó y finalizó el desarrollo de cada una de las feature branches.
Ahora toca prepararlo todo para hacer el release a producción, aunque eso lo haremos en la siguiente entrega.
Hemos subido este repositorio a nuestra cuenta de github. Podéis verlo en este enlace: https://github.com/aprendegit/articulo-sobre-gitflow
































 del repositorio original al fork")

